Telemetry Guide
At GitLab, we collect telemetry for the purpose of helping us build a better GitLab. Data about how GitLab is used is collected to better understand what parts of GitLab needs improvement and what features to build next. Telemetry also helps our team better understand the reasons why people use GitLab and with this knowledge we are able to make better product decisions.
We also encourage users to enable tracking, and we embrace full transparency with our tracking approach so it can be easily understood and trusted. By enabling tracking, users can:
- Contribute back to the wider community.
- Help GitLab improve on the product.
This documentation consists of three guides providing an overview of Telemetry at GitLab.
Telemetry Guide:
- What is Usage Ping
- Usage Ping payload
- Disabling Usage Ping
- Usage Ping request flow
- How Usage Ping works
- Implementing Usage Ping
- Developing and testing usage ping
- What is Snowplow
- Snowplow schema
- Enabling Snowplow
- Snowplow request flow
- Implementing Snowplow JS (Frontend) tracking
- Implementing Snowplow Ruby (Backend) tracking
- Developing and testing Snowplow
More useful links:
Our tracking tools
In this section we will explain the six different technologies we use to gather product usage data.
Snowplow JS (Frontend)
Snowplow is an enterprise-grade marketing and product analytics platform which helps track the way users engage with our website and application. Snowplow JS is a frontend tracker for client-side events.
Snowplow Ruby (Backend)
Snowplow is an enterprise-grade marketing and product analytics platform which helps track the way users engage with our website and application. Snowplow Ruby is a backend tracker for server-side events.
Usage Ping
Usage Ping is a method for GitLab Inc to collect usage data on a GitLab instance. Usage Ping is primarily composed of row counts for different tables in the instance’s database. By comparing these counts month over month (or week over week), we can get a rough sense for how an instance is using the different features within the product. This high-level data is used to help our product, support, and sales teams.
Read more about how this works in the Usage Ping guide
Database import
Database imports are full imports of data into GitLab's data warehouse. For GitLab.com, the PostgreSQL database is loaded into Snowflake data warehouse every 6 hours. For more details, see the data team handbook.
Log system
System logs are the application logs generated from running the GitLab Rails application. For more details, see the log system and logging infrastructure.
What data can be tracked
Our different tracking tools allows us to track different types of events. The event types and examples of what data can be tracked are outlined below.
| Event Type | Snowplow JS (Frontend) | Snowplow Ruby (Backend) | Usage Ping | Database import | Log system |
|---|---|---|---|---|---|
| Database counts | |||||
| Pageview events | |||||
| UI events | |||||
| CRUD and API events | |||||
| Event funnels | |||||
| PostgreSQL Data | |||||
| Logs | |||||
| External services |
Database counts
- How many Projects have been created by unique users
- How many users logged in the past 28 day
Database counts are row counts for different tables in an instance’s database. These are SQL count queries which have been filtered, grouped, or aggregated which provide high level usage data. The full list of available tables can be found in structure.sql
Pageview events
- How many sessions visited the /dashboard/groups page
UI Events
- How many sessions clicked on a button or link
- How many sessions closed a modal
UI events are any interface-driven actions from the browser including click data.
CRUD or API events
- How many Git pushes were made
- How many GraphQL queries were made
- How many requests were made to a Rails action or controller.
These are backend events that include the creation, read, update, deletion of records and other events that might be triggered from layers that aren't necessarily only available in the interface.
Event funnels
- How many sessions performed action A, B, then C
- What is our conversion rate from step A to B?
PostgreSQL data
These are raw database records which can be explored using business intelligence tools like Sisense. The full list of available tables can be found in structure.sql
Logs
These are raw logs such as the Production logs, API logs, or Sidekiq logs. See the overview of Logging Infrastructure for more details.
External services
These are external services a GitLab instance interacts with such as an external storage provider or an external container registry. These services must be able to send data back into a GitLab instance for data to be tracked.
Telemetry systems overview
The systems overview is a simplified diagram showing the interactions between GitLab Inc and self-managed nstances.
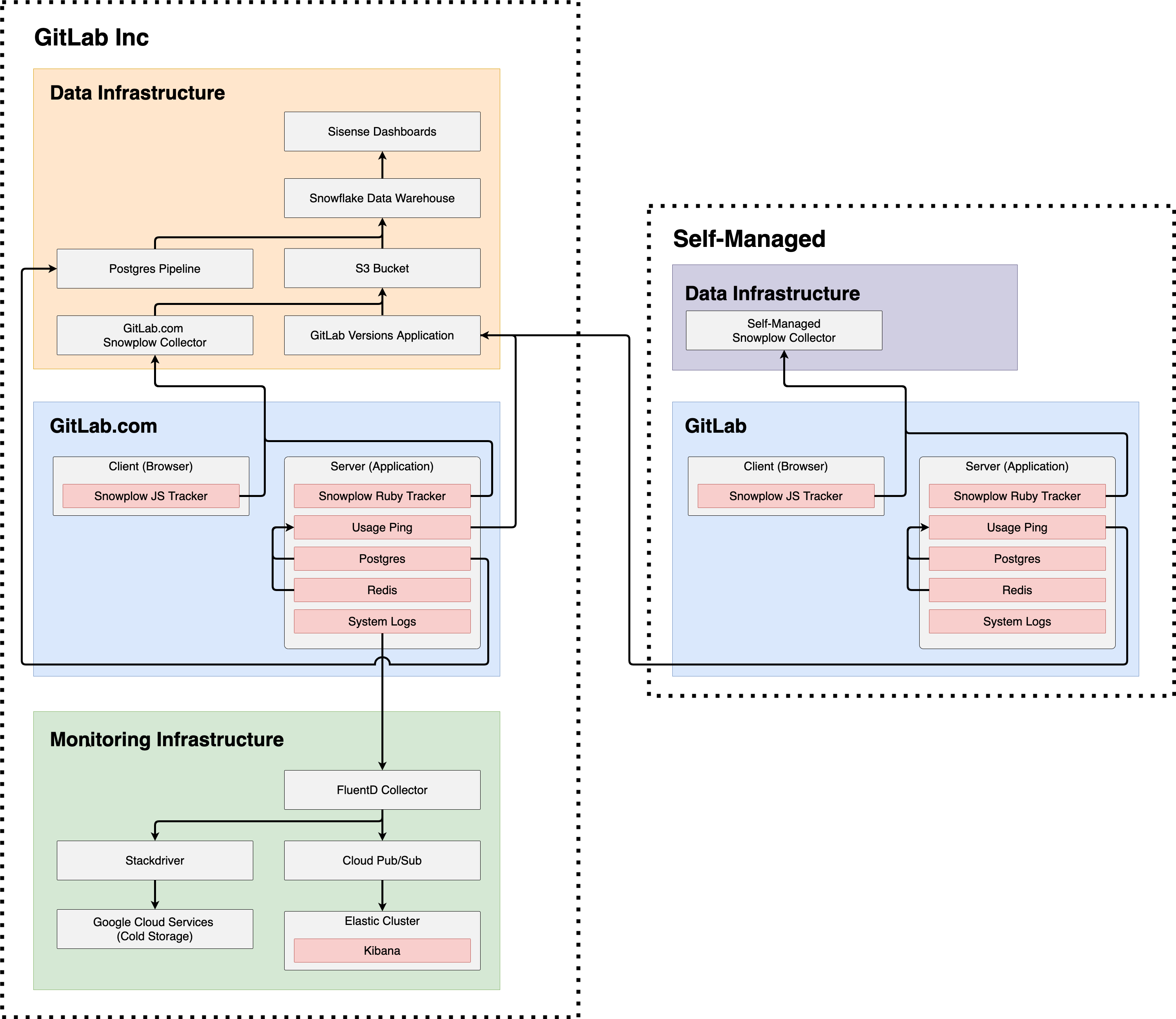
GitLab Inc
For Telemetry purposes, GitLab Inc has three major components:
- Data Infrastructure: This contains everything managed by our data team including Sisense Dashboards for visualization, Snowflake for Data Warehousing, incoming data sources such as PostgreSQL Pipeline and S3 Bucket, and lastly our data collectors GitLab.com's Snowplow Collector and GitLab's Versions Application.
- GitLab.com: This is the production GitLab application which is made up of a Client and Server. On the Client or browser side, a Snowplow JS Tracker (Frontend) is used to track client-side events. On the Server or application side, a Snowplow Ruby Tracker (Backend) is used to track server-side events. The server also contains Usage Ping which leverages a PostgreSQL database and a Redis in-memory data store to report on usage data. Lastly, the server also contains System Logs which are generated from running the GitLab application.
- Monitoring infrastructure: This is the infrastructure used to ensure GitLab.com is operating smoothly. System Logs are sent from GitLab.com to our monitoring infrastructure and collected by a FluentD collector. From FluentD, logs are either sent to long term Google Cloud Services cold storage via Stackdriver, or, they are sent to our Elastic Cluster via Cloud Pub/Sub which can be explored in real-time using Kibana
Self-managed
For Telemetry purposes, self-managed instances have two major components:
- Data infrastructure: Having a data infrastructure setup is optional on self-managed instances. If you'd like to collect Snowplow tracking events for your self-managed instance, you can setup your own self-managed Snowplow collector and configure your Snowplow events to point to your own collector.
- GitLab: A self-managed GitLab instance contains all of the same components as GitLab.com mentioned above.
Differences between GitLab Inc and Self-managed
As shown by the orange lines, on GitLab.com Snowplow JS, Snowplow Ruby, Usage Ping, and PostgreSQL database imports all flow into GitLab Inc's data fnfrastructure. However, on self-managed, only Usage Ping flows into GitLab Inc's data infrastructure.
As shown by the green lines, on GitLab.com system logs flow into GitLab Inc's monitoring infrastructure. On self-managed, there are no logs sent to GitLab Inc's monitoring infrastructure.
The differences between GitLab.com and self-managed are summarized below:
| Environment | Snowplow JS (Frontend) | Snowplow Ruby (Backend) | Usage Ping | Database import | Logs system |
|---|---|---|---|---|---|
| GitLab.com | |||||
| Self-Managed |
|
|
Note (1): Snowplow JS and Snowplow Ruby are available on self-managed, however, the Snowplow Collector endpoint is set to a self-managed Snowplow Collector which GitLab Inc does not have access to.